
Python 实现基于 Slidev 在线 PPT 生成的 MCP 服务器
前言
从 2022 年 12 月份 chatgpt 横空出世,我们见证了 AI 技术的进步,同时也在思考一个非常关键的问题:
如何才能利用 AI 降低我们的工作时间,提升我们的工作效率?
仅仅通过自然语言进行交互的网页版大模型,显然能力有限,就在此刻,AI Agent 技术基于大模型,给出了上面那个问题更多的可能性。
制作 PPT 是一个我们常见的任务,无论是工程师还是学者,大家总是需要制作一份 ppt 来汇报自己的工作,展示自己的思想,那么不知道大家有没有思考过这么一个问题:我们如何才能只专注于 ppt 的内容,能否让 AI 帮我们完成 ppt 其余我们不关心的部分的书写(比如样式,文字大小等等与内容无关的体力活)。
只靠网页大模型显然,能力有限,因为网页大模型只能输出文本;市面上也有不少 AI PPT 产品,比如 gamma,WPS AI,MindShow 等等,但是这些产品并没有很好的普及,一定的操作门槛无疑成为了阻挡用户和伟大功能的「最后一公里」。但是现在有了完全可以只通过自然语言就能进行交互的大模型,那么我们能不能做出一些新的可能性呢?
答案是可以,这篇文章就将演示一下如何开发一款能帮我们进行 slidev ppt 开发的 MCP 并利用 openmcp 完成功能模块的验证和测试。测试完成的 MCP 作为插件装载进入任意一个 MCP 客户端就能直接成为一个帮我们自动根据大纲制作可以在网页上浏览的在线 ppt 的 AI Agent 了。
环境准备
为了进行了本篇文章,你需要准备如下的开发环境:
- python 3.10 以上版本
- nodejs 18.0.0 以上版本
- vscode 或者 trae 或者 cursor
- 安装插件 OpenMCP
本期文章代码在:https://github.com/LSTM-Kirigaya/slidev-mcp
什么是 slidev
Slidev 是一款专为开发者设计的现代化、基于 Markdown 和 Vue.js 的开源幻灯片制作工具,旨在让用户通过简单的文本语法创建高度可定制且交互性强的演示文稿。在开始后续的内容之前,我想要带大家先玩玩 slidev,初步建立一个基本印象,这样我们后续构建智能体来自动帮我们构建 PPT 时,逻辑才会更加明晰。
开始一个超级简单的网络 PPT
首先打开命令行,先安装一下 slidev
npm i -g @slidev/cli安装完成后,我们创建第一个 Slidev 的 PPT,此处就以 slidev 官网上的例子,我们创建 demo.md,然后在下面填充如下内容:
# Title
Hello, **Slidev**!
---
# Slide 2
使用代码块来高亮代码:
```ts
console.log('Hello, World!')
```
然后我们启动 slidev 来看看效果,在命令行中输入:
slidev demo.md这句命令会将 demo.md 看作 slidev 幻灯片的入口文件并执行编译渲染。执行完成后,命令行会输出这样的字样:
public slide show > http://localhost:3030/这个时候,我们复制一下 http://localhost:3030/,然后打开浏览器,并在搜索边框中粘贴进入,按下回车,你就可以看到渲染好的 PPT 了:
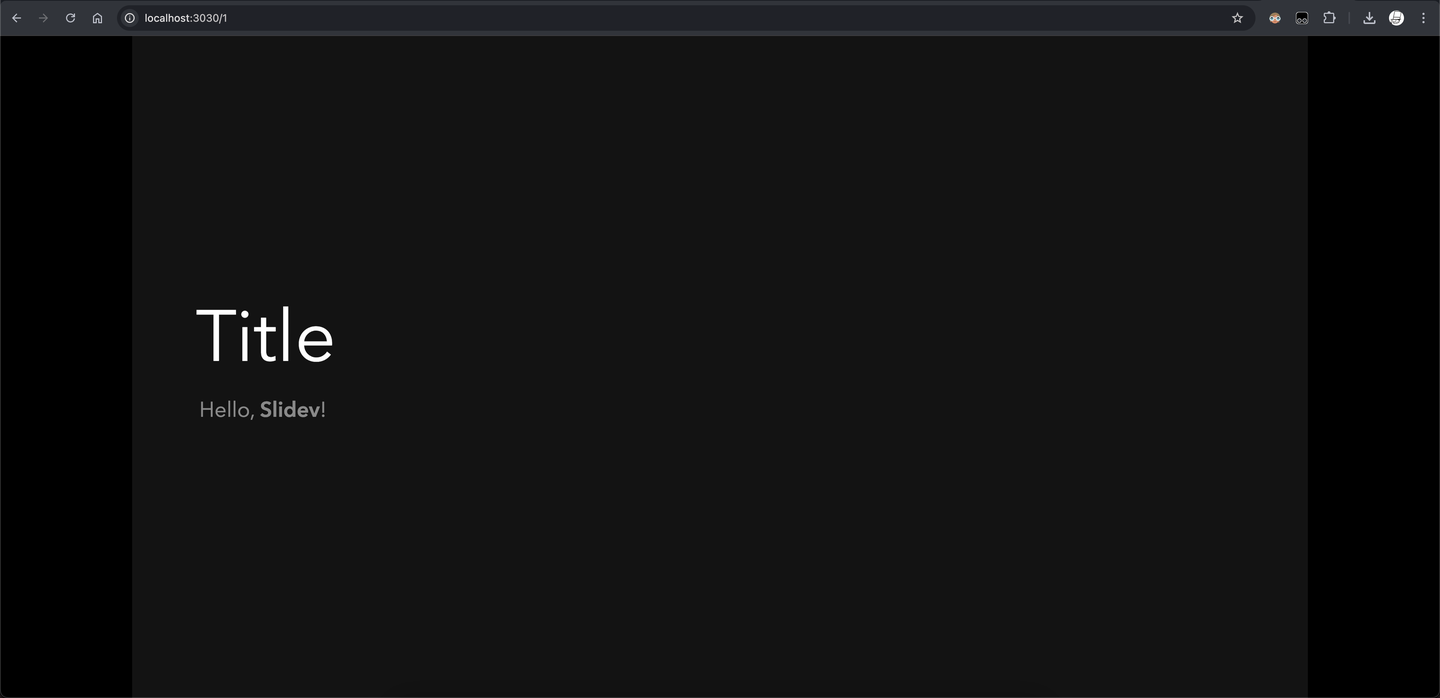
把光标移动到左下角还能看到一个隐藏的工具栏,可以切换主题颜色、全屏、查看栅格视窗;按下方向键的左右可以切换不同的幻灯片。
添加转场动画
从上面的案例中大家应该也能看出来了,slidev 使用 --- 分隔符来确定不同的页面。--- 就是另起一页,有点像是 latex 里面的 \newpage。
事实上,除了 --- 外,Slidev 还支持使用 frontmatter 作为分割符,比如:
---
value1: key1
value2: key2
---这里我们通过了如下的这个被称为 frontmatter 的特殊语法单元定义了当前幻灯片的属性。slidev 提供了很多内置的属性,比如我们可以设置 transition: slide-left 来设置这页 PPT 的入场动画。
---
transition: slide-left
---
# Title
Hello, **Slidev**!
---
transition: slide-left
---
# Slide 2
使用代码块来高亮代码:
```ts
console.log('Hello, World!')
```
效果如下:

除此之外,slidev 还提供了一大堆其他的功能和特性,都需要制定各种各样的样式和 frontmatter 来制定。这些都可以在他们的 官方文档中看到
看到这里,我知道你有一种想要退出的欲望了。先别急!我也觉得 Slidev 的使用非常麻烦,这也是这篇文章的目的。上面我列出的例子并非在教会你如何使用 slidev,而是通过一种目视的身体力行,让我的观众知道 slidev 的使用并不简单,这样才为我们开发 Slidev 的 Agent 创建了逻辑上的“正确性”。
编写 Slidev MCP
写 slidev 真的麻烦
在之前的演示中,大家可以看到,通过简单的 markdown,我们就可以创建出简洁优雅的 ppt,但是 Slidev 因为上手门槛高,中长篇ppt编写繁琐,slidev 编写者心智负担过大等原因,导致 slidev 这项技术一直无法很好地普及。
如果你真的跟着上面的步骤走过,还点进了官方提供的文档,看到一大堆非常麻烦的 html,有一种放弃的冲动的时候,那么你一定能理解我打算做的事情。
直接用大模型生成 Slidev
在正式开始之前,肯定有朋友要问了:既然 slidev 也是纯文本,为什么不让大模型直接生成呢?有如下几点原因:
- slidev 使用了特殊的 markdown 语法,大模型并不认识这些语法单元,导致生成的效果会很差。
- slidev 通过
---定义了多页 ppt,你询问大模型每次都要重新生成每一页的 ppt,不仅效率低下,而且因为生成范围变大了,大模型犯错的概率也提升了。
感兴趣的读者可以在这篇文章结束后,把相同的问题塞入大模型来测试效果。直接使用大模型无法解决我们的问题,所以我们不得不编写 Agent 来优化这个过程。
编写我们的 Slidev Agent
好了,我们准备开始编写我们的 Slidev Agent,来帮我们自动编写 PPT,对于 AI Agent 和 MCP 基础知识缺乏的朋友我在这里强烈推荐看一下我之前的博客:
第一步:确定基本的 Agent 技能
编写 AI Agent 的第一步就是要先确定我们的 agent 具备哪些基本技能。
我们根据我们自己开发 slidev 的经验,不难总结出如下的几条基本的技能(或者说步骤):
- 检查 Node.js 和 Slidev CLI 是否安装就绪 (没有的话自动安装)
- 创建新的 Slidev 项目(需获取用户输入的标题和作者信息)
- 加载现有 Slidev 项目
- 创建/更新封面页(支持自定义模板和背景图片)
- 添加新幻灯片页面(支持多种布局和内容格式)
- 修改现有幻灯片内容
- 获取特定幻灯片内容
第二步:实现基本技能
实现 Agent 基本技能我们通过 mcp 工具 来实现。打开 vscode 或者别的代码编辑器,我们先完成上述技能的 python 实现。
需要注意的是,这里我们采用全局变量来保存当前的 slidev ppt 的状态,比如当前有多少页 ppt ,每一页 ppt 都是什么内容呀等等。
这里需要我们根据我们关于 slidev 的知识来编写对应的工具,比如我们在编写正常一页 slidev 的代码可能如下:
---
layout: default
transition: slide-left
---
## Hello World !然后,为了减轻用户的思维负担,我决定把所有的转场动画 transition 全部指定为 slide-left,然后布局 layout 就让 AI 自己决定,那么假设你已经确定了这样的需求模式,上面的例子对应的 python 的字符串模板就是:
template = f"""
---
layout: {layout}
transition: slide-left
---
{content}
"""其中,layout 就是 default,content 就是 ## Hello World !,当然,这些接口都是预留给大模型,让大模型来帮我们生成的。
所以增加一页 ppt 的 mcp 工具 就可以如此编写:
@mcp.tool(
description='Add new page.'
)
def add_page(content: str, layout: str = "default") -> SlidevResult:
global SLIDEV_CONTENT
if not ACTIVE_SLIDEV_PROJECT:
return SlidevResult(False, "No active Slidev project. Please create or load one first.")
template = f"""
---
layout: {layout}
transition: slide-left
---
{content}
""".strip()
SLIDEV_CONTENT.append(template)
page_index = len(SLIDEV_CONTENT) - 1
save_slidev_content()
return SlidevResult(True, f"Page added at index {page_index}", page_index)这里给大家一个简单的小提示,设置这些接口有几个基本准则:
- 函数尽量不能设置复杂数据结构作为参数,参数最好就设置成字符串或者数字。
- 一定要确保填入的参数是大模型大概率知道的东西,比如上面填入的是 slidev 的布局字符和文本内容。文本内容是基于上下文生成的 markdown,我们认为大模型知道;下面的 mcp 工具 就是一个反面例子:python
# 错误的例子:因为大模型并不知道最新的 Windows 激活码 @mcp.tool(description='激活 Windows') def activate_windows(activation_code: str): winapi.activate(activation_code)
知晓上述的基本逻辑后,就可以编写出最终的代码了,完整代码在 https://github.com/LSTM-Kirigaya/slidev-mcp/blob/main/tutorial/step1.py
第三步:测试 MCP 工具流
为了测试我们编写的 mcp 工具 是否不报错且能达到基本的效果,我们很有必要对 MCP 进行两轮基本测试。
第一轮测试是基本的工具测试,目的是检测 mcp 工具 是否存在运行时错误,我们先点击 vscode 应用商城,搜索 openmcp
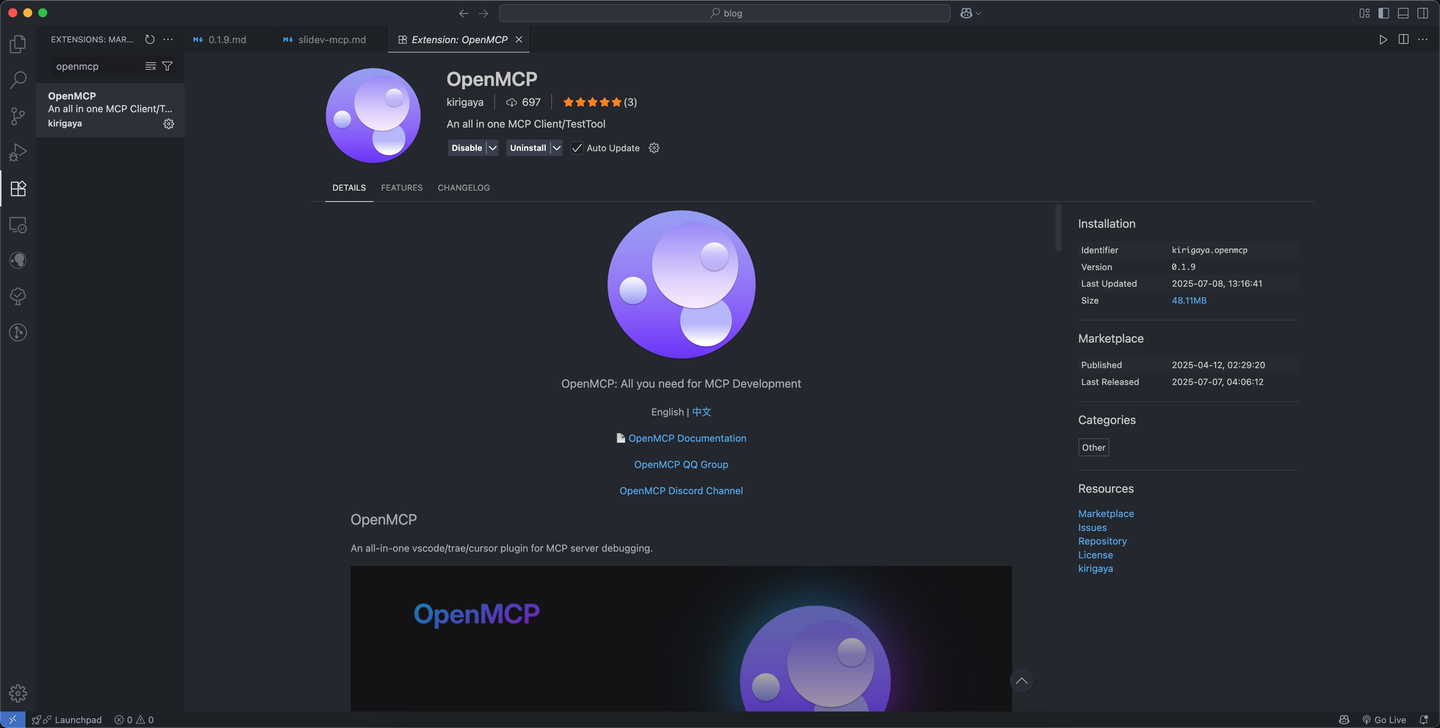
点击下载即可,然后进入刚才我们编写的 python 文件,点击右上角的 openmcp 图标进入 openmcp 调试编辑器,初始化时会出现一个基本的引导界面,大家认真走完一遍即可。
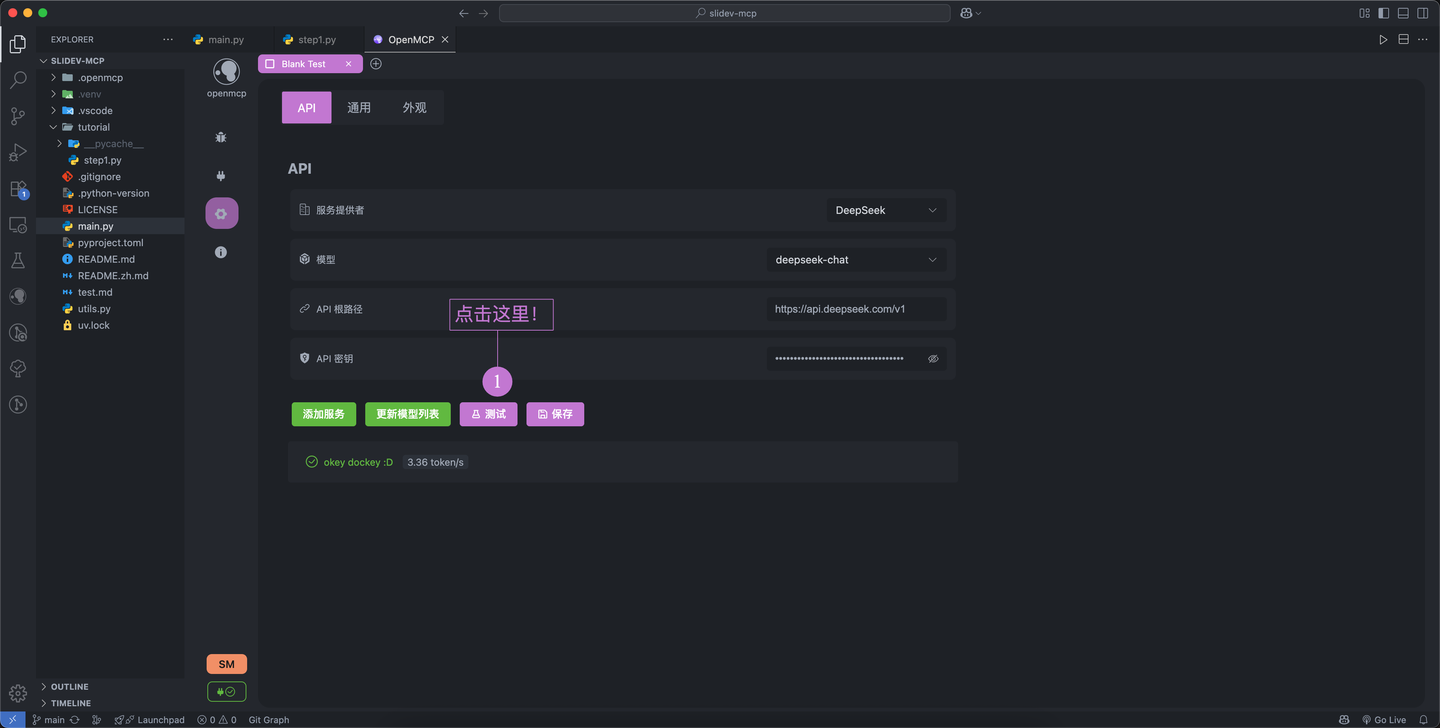
进入编辑器后,先配置一下大模型的 API,我这里使用的是 deepseek 的 api,填入 api token,然后点击保存即可。没有 api token 的朋友可以进入 deepseek 开放平台 来注册并获取,新用户是默认拥有20块钱的额度的。获取 deepseek api token 后,把 token 填入 openmcp 的大模型配置栏目即可,然后点击保存。
我们再点击一下测试,如果出现了下图的结果,说明你的大模型现在可以直接使用了。
然后我们点击最上面的「空白测试」,点击画面中央的「工具」,此处就可以看到我们定义的所有 mcp 工具了,为了快速测试我们的工具是否存在运行时的问题,我们可以点击「工具模块」右侧的「工具自检」,此时会弹出一个窗口,展示我们设定好的调度顺序。
这里一定要注意了!我们编写的 mcp 工具 一般会存在一定的调度顺序,比如在我们开发的 slidev-mcp 中,大模型必须先调用 create_slidev 或者 load_slidev 才能继续执行后续的操作,在默认生成的调度图中,这个顺序是正确的,但是如果是读者自己未来开发的其他的 MCP,这个 mcp 工具 的顺序未必是正确排布的,这个时候就需要手动调整一下拓扑结构,这个部分的使用请看 openmcp 0.1.9 的视频讲解:https://www.bilibili.com/video/BV1YpGHzcEs4
准备就绪后,点击上方的「开启自检程序」,点击「确定」即可,稍等片刻,openmcp 会自动完成所有工具的检查,出现下图这样全部亮起 success 字样的结果时说明测试成功:
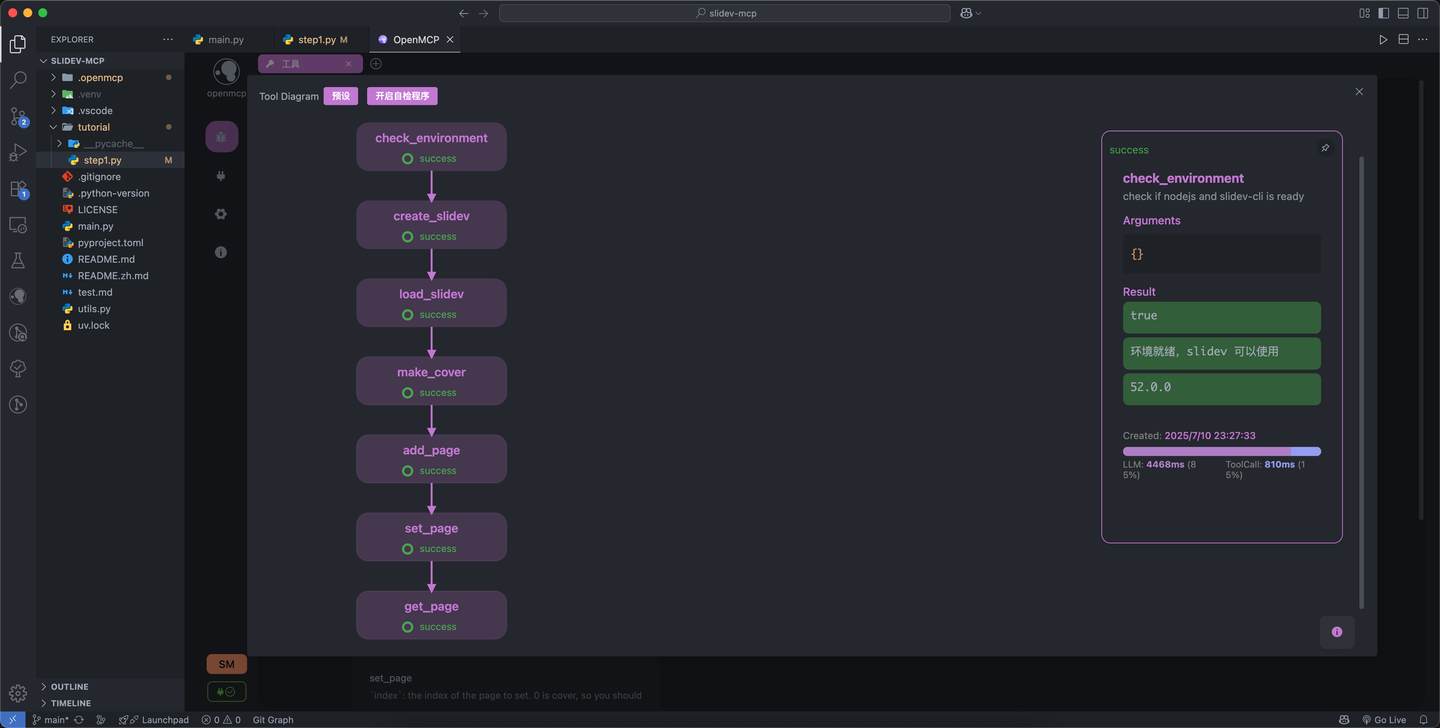
这一步在 MCP 开发初期非常有用,它可以有效减少我们后续在进行交互式测试时出现的问题从而浪费时间的概率。
第四步:交互测试 MCP
自检程序完成后说明你的 mcp 工具没问题了,这个时候就可以直接在「交互测试」中测试一下我们的 mcp 接入大模型后组装成的 Agent 效果如何了!
我们新建一个空白测试,然后选择「交互测试」,这个时候你就会进入一个很眼熟的对话框,这个对话框和你平时使用的大模型的别无二致,通过这个功能,我们可以在不进行 mcp 安装的情况下就测试我们开发的 agent 效果如何。
我们在对话框中粘贴我们事先准备好的一个草拟好的演讲提纲
你可以直接把任意大段文本丢给大模型,让大模型帮你生成类似这样的提纲,这里就涉及到一个可以将网站链接转换成 markdown 的项目 crawl4ai 了,此处不做赘述了,网上关于 crawl4ai 也有对应的 mcp,大家可以把它作为额外的服务器载入 openmcp 中。在 openmcp 中连接多个服务器的教程可以看 这里 .
# 讲演提纲:从大模型的幻觉现象剖析开发 AI Agent 的技术瓶颈和解决思路
## 封面页
- **标题**:从大模型的幻觉现象剖析开发 AI Agent 的技术瓶颈和解决思路|到底谁的幻觉更大?
- **作者**:锦恢 (LSTM-Kirigaya)
- **背景图**:使用文章中的首张配图([链接](https://linux.do/uploads/default/original/4X/4/c/3/4c34eab8281f0d6215f2ea4139df019dcfc7212d.webp))
- **副标题**:探讨 AI Agent 开发中的核心挑战与解决之道
---
## 1. 前言
- **讲演者背景**:
- Blender MCP 开发者
- OpenMCP 项目作者
- **核心问题**:
- AI 领域 Demo 多但实用产品少
- 两大关键问题:
1. 大模型的幻觉
2. 开发者的幻觉
---
## 2. 大模型的幻觉
### 定义
- 大模型不知道自己不知道什么,遇到未知问题时会胡编乱造。
- 核心表现:
- 盲目假设(如数据库查询案例)
- 虚构答案
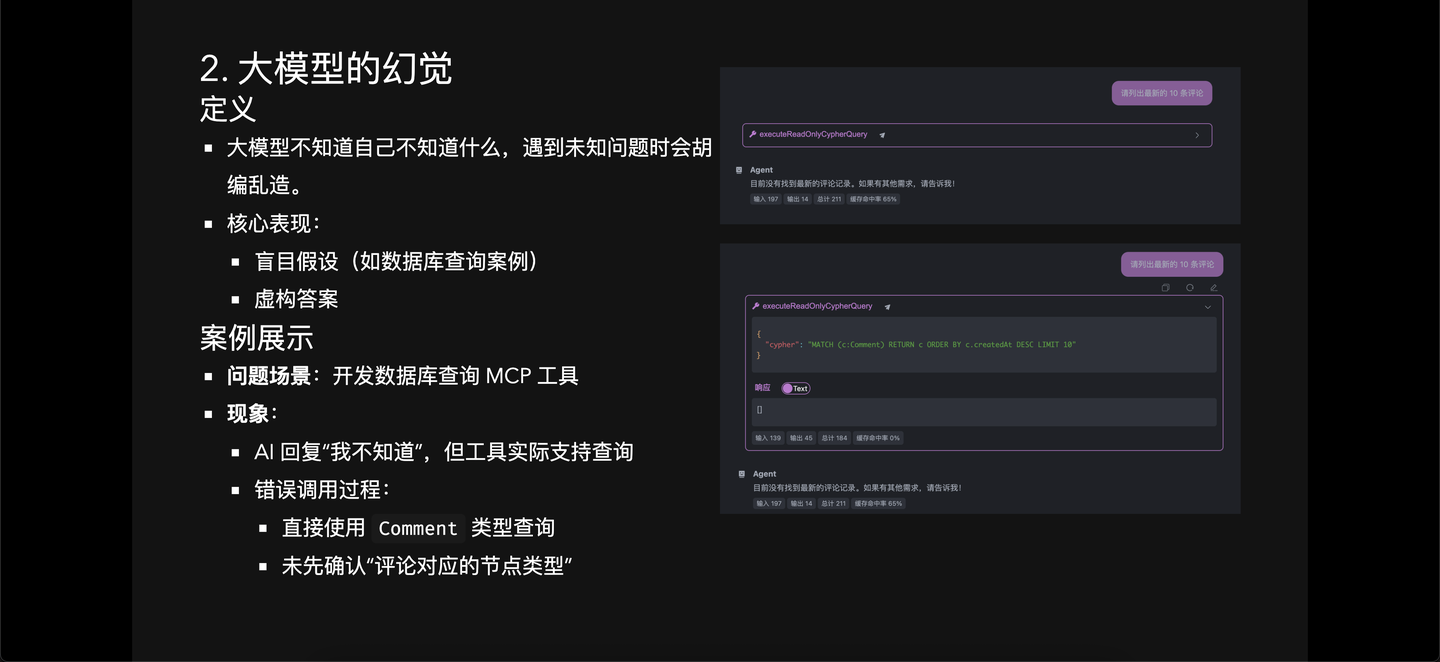
### 案例展示
- **问题场景**:开发数据库查询 MCP 工具
- **现象**:
- AI 回复“我不知道”,但工具实际支持查询
- 错误调用过程:
- 直接使用 `Comment` 类型查询
- 未先确认“评论对应的节点类型”
- **配图**:
- [错误回复截图](https://linux.do/uploads/default/original/4X/2/0/1/2019c1c00096d36d9c6c5a2d229e78726e9009df.png)
- [错误调用过程截图](https://linux.do/uploads/default/original/4X/2/4/b/24baa4fb174e2dea422a59850bd420b57ca44fdc.png)
---
## 3. 解决大模型幻觉的方法
### 前提条件
- 明确 **应用场景** 和 **设计边界**:
- AI Agent 能做什么?不能做什么?
### 具体方法
1. **系统提示词**:
- 明确告知 AI 能力边界
- 提供清晰的指令模板
2. **MCP 工具原子化拓展**:
- 细化查询能力(如先查询“评论节点类型”)
### 效果展示
- **优化后结果**:
- AI 正确识别节点类型
- 返回结构化数据
- **配图**:
- [优化结果截图](https://linux.do/uploads/default/original/4X/2/4/7/247aa5b0ff8adc857f1f3a57cb4351989a6b5954.jpeg)
---
## 4. 开发者的幻觉
### 核心问题
- 开发者对大模型能力边界的不切实际期望
- **现实背景**:
- Pretrain Scaling Law 已接近极限
- 大模型能力边界逐渐清晰
### 具体表现
- 在不适合的领域强行开发 AI Agent
- 失败后归咎于“大模型太垃圾”
- 忽视设计边界和方法论
### 警示
- 开发者需:
1. 学习 AI 底层技术
2. 理性认识大模型局限
3. 避免“饭圈化”思维
---
## 5. 结论与 OpenMCP 介绍
### 核心总结
1. 大模型幻觉:不知道自己不知道什么
2. 开发者幻觉:对能力边界的不切实际期望
3. 两者均为 AI Agent 开发的核心障碍
### OpenMCP 项目
- **定位**:一体化 MCP 开发与部署解决方案
- **资源**:
- [官方站点](https://kirigaya.cn/openmcp)
- [GitHub](https://github.com/LSTM-Kirigaya/openmcp-client)
- **呼吁**:
- “AI 时代不要抛弃自己的大脑”
---
## 附录(可选)
- **参考文献**:
- 文中提到的 OpenMCP 教程链接
- 相关技术术语解释(如 Pretrain Scaling Law)
- **Q&A 环节**:预留观众提问时间然后我们询问:
请帮我把下面的大纲做成 slidev ppt:
{{content}} 的地方就复制上面的大纲的文本内容。按下回车即可看到大模型会帮我们逐步进行执行:
注意了!如果你的大模型厂商不支持原生的「函数调用」(也就是询问的时候会报错,不过常见的 deepseek,qwen 等等 openmcp 内置的模型都是支持 函数调用),可以尝试把工具栏下面的「开启 XML 指令包裹」开起来:
更多关于 openmcp 「交互测试」的使用方法,可以移步 官方文档.
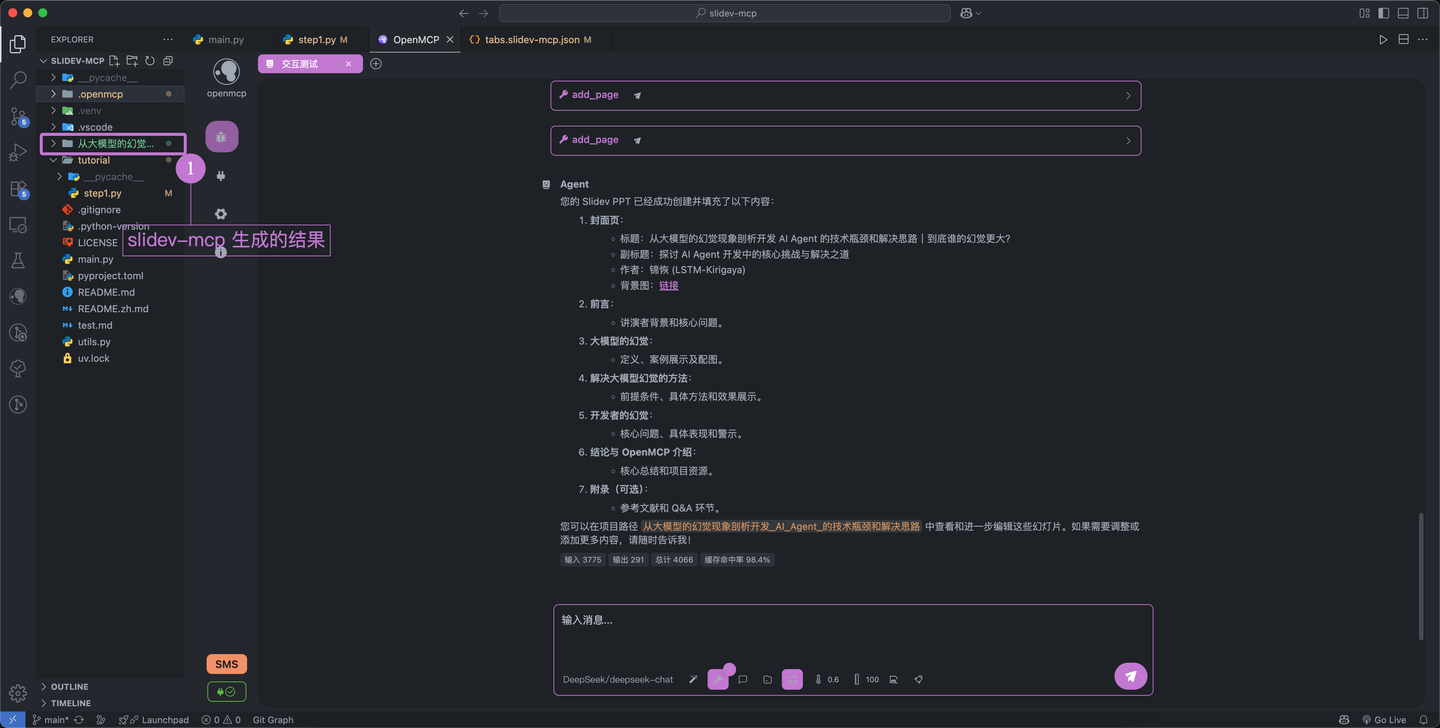
稍等片刻,就能看到 slidev mcp 生成的结果了:
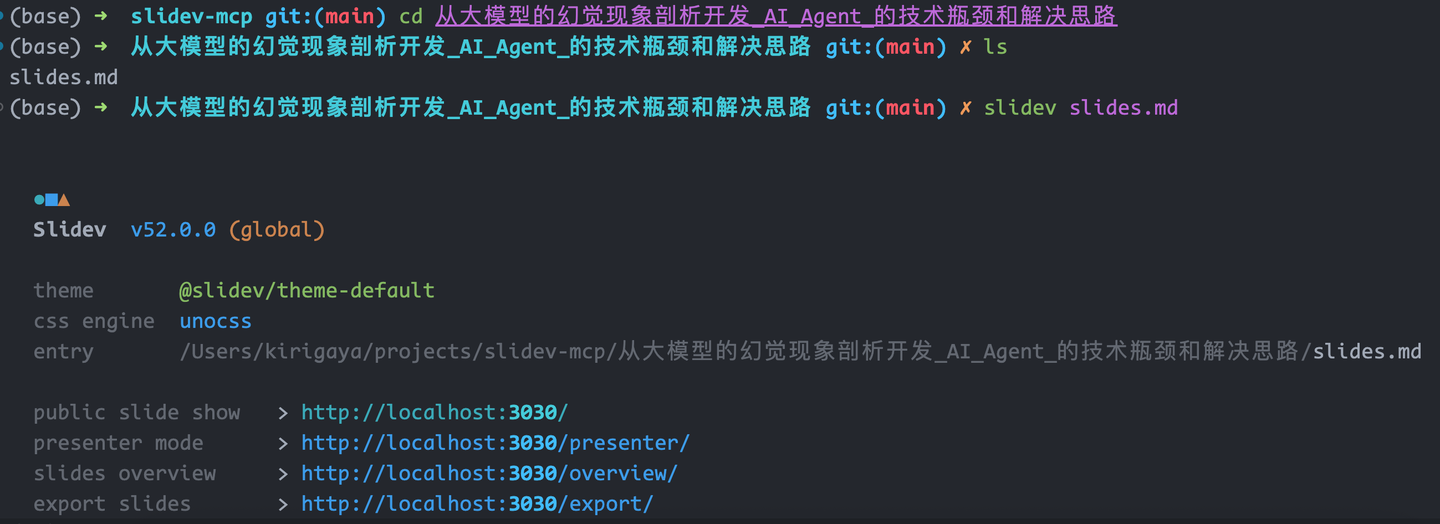
我们进入这个文件夹,然后运行服务器:
你就可以看到我们生成的效果:

PPT 架子是生成了,但是效果嘛,就有点不尽如人意了。根本原因在于大模型对于部分参数缺少了上下文,导致胡乱填写。比如大模型不知道封面图要放什么,所以它只会自己从大纲里面找到第一个。
下面这一页也有问题:

我们想要渲染出这张图,但是 agent 给出的渲染结果却是两个链接,这也是不对的。所以,在第一轮交互测试后,我们就有必要开始进行第一次的迭代了。
AI Agent 开发须知:永远不要认为你能一次性就开发出完美的 Agent,Agent 一定要在反复迭代和测试中不断改进。
第五步:根据交互测试结果反复迭代 mcp 工具
针对之前的问题,我们可以从如下两个角度出发,进行改进:
我们在之前的代码中添加如下的代码:
然后我们启动第二版本的 slidev mcp,点击交互测试,我们先按照下面的步骤来选中我们刚刚创建的 prompt
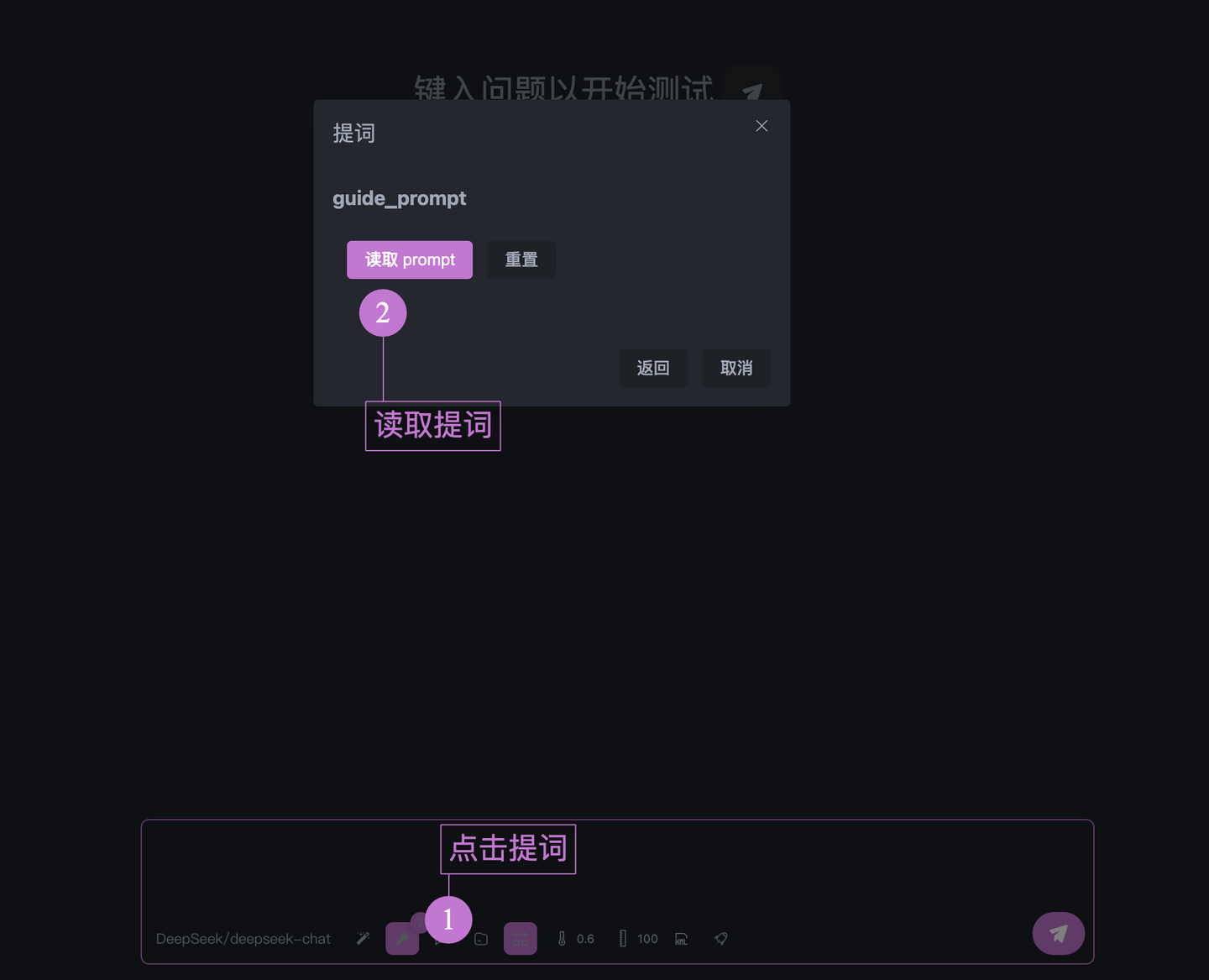
在正式启动之前,记得先删除之前生成的文件夹(因为 slidev mcp 实现了读取存在的 ppt 的功能,如果读取后再修改,那么本文后面案例的复现难度就会提升)
等待生成后,可以看到,此时的 PPT 就变成正常的双栏结构了,左侧文字,右侧图片。
当然,根据你的领域知识,可能生成的 ppt 还存在其他地方的问题,那么就需要进行下一轮迭代,直到迭代到让你满意为止。
第六步:导出 mcp 配置文件
如果你的测试已经让你满意,那么你就可以选择将你的结果导出,点击工具栏最右的「导出 mcpconfig」,然后会出现一个对话框:
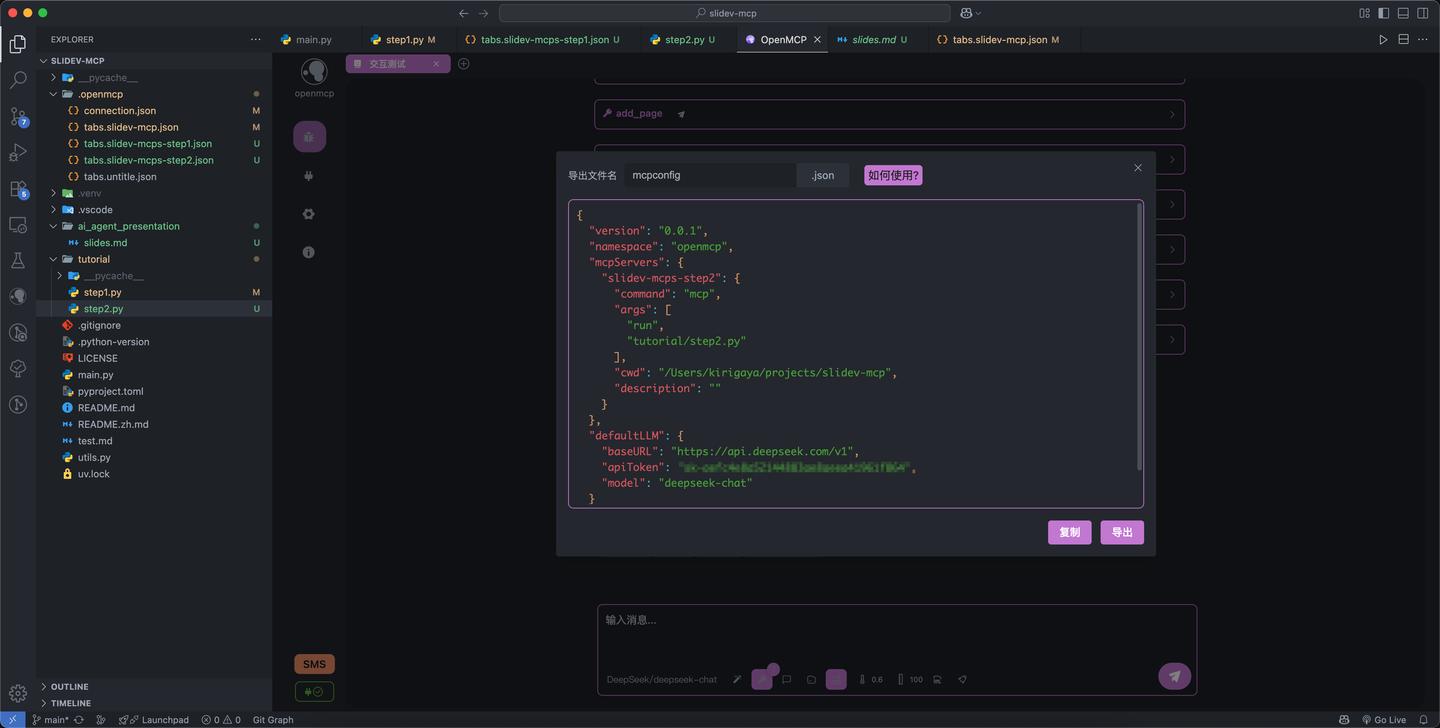
选择导出或者复制都行,复制出的配置文件,可以直接载入 Claude Desktop 或者 Cherry Studio 中,也可以根据此处的教程,使用 openmcp-sdk 直接部署到你的服务或者程序中。
结论
好啦!相信通过这篇教程,大家应该能够更加直观地了解到 AI Agent 的一个基本开发流程,以及 mcp 是什么,如何调试和部署了。
想要了解更多的 Agent 开发信息,可以浏览一下 OpenMCP 的官网,那里面提供了不少的使用教程和开发案例。
 LSTM-Kirigaya (锦恢)
LSTM-Kirigaya (锦恢)